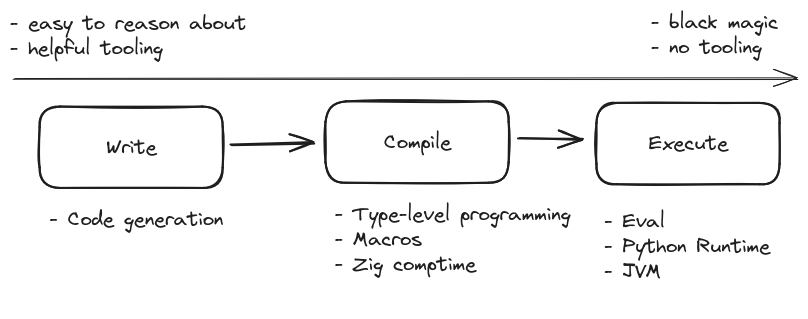
The main point of programming is to produce instructions that are executed by a computer. By this definition, you are programming if you are creating or changing the instructions that a computer executes. I argue that in a typical write-compile-run scenario, programming can happen at each of those three steps, but the tooling for those steps can be wildly different. My recommendation is to err on the side of write-time programming: use code generators and check in the code they generate rather than trying to use compile-time magic or super-dynamic features.
A lot of programming languages grow systems that modify the code at compile-time.
C has the preprocessor, Lisp has macros (so does Rust), C++ has templates, Zig has comptime, etc.
The system that modifies the code at compile-time is (usually) Turing complete.
This is unsurprising, since it's difficult to make systems that are not Turing complete.
So these code modification systems and "normal" programming are two sides of the same coin.
The only difference lies in when the code is executed.
This is the insight what caused Zig to have comptime: at compile-time, you program in the same language that you program in normally.
This is tricky, of course, since the environment that you are compiling in is not the same that you are running the code in (at the very least, time will have passed), but it's an interesting idea against the alternative of having an entirely separate language that you only use once in a blue moon.
Another prominent form of compile-time programming happens in type systems. Types unlock compiler optimizations because they provide extra information to the compiler about the program, and so influence the code that's being generated. More drastically, an incorrectly typed program will fail to compile and not produce any code, which is also an influence on the code being generated. In general, type systems can be pretty powerful.
You can do run-time programming in language that have a mechanism to dynamically generate code while the program is running, and execute it.
For instance, you can do this in Python with strings and eval.
This allows you to tailor the code that is being run to the data in your program.
eval is less popular these days since it tends to lead to massive security holes, but a similar thing happens with class hooks, where you modify a class definition based on data available only when the program is running.
A bit more mind-bending to think about is the fact that if you write Java code, the compiler turns it into JVM bytecode rather directly into instructions. This JVM bytecode gets executed by the JVM runtime. We say "executed", but what that really means is that the JVM runtime converts bytecode into actual computer instructions. That's creating instructions that a computer executes, and therefore run-time programming!
A natural question to ask is if we can move run-time programming to compile-time. This can be done in Python with tools like Numba or Nuitka and in Java with GraalVM, but is often difficult because the code produced by run-time programming can depend on runtime-known (e.g. user) input.
To push the observation to its natural conclusion: the process of using the program or something providing input to the program is also a form of programming! Although the program is created in a extremely domain-specific language, hand-crafted for the task at hand, it is programming nonetheless.
The problem with both run-time programming and compile-time programming is that is that it can become very hard to keep figure out what exactly is going to happen: you never know if some library is going to hook into your code and rewrite all your classes's __init__-methods.
And even if you are "only" using macros or comptime, you are prevented from straightforwardly reading the code top-to-bottom to see what is happening (this is also what I don't like about a lot of object-oriented code).
Aside from the human element, it also makes static analysis more difficult, meaning your development tools are able to help you less.
An alternative pattern I've taken to using (for instance in Pydantic-SQL-bridge) is to generate the code, and keep that as part of the source for the program. I use the computer to write part of the program for me, leading to what you might term "programming-time programming". To the rest of the system that ensures that the code get executed, it is the same as code that I wrote myself. Type-checking, usage search, dead-code analysis, linting, and source control diffs all work great on it!
The tradeoff is that you have to step a bit more careful around the code that you generate. [1] If you modify the code that you generated, the generating code becomes useless, because it cannot easily reproduce the generated code. In practice I find this a worthwhile tradeoff: I work in small teams with responsible adults who know to read the comment at the top of the file that says "GENERATED BY script_x.py DO NOT MODIFY".
It's programming all the way down. Writing code, generating boilerplate in your IDE, modifying code at compile-time, executing the code at run-time, and using the program are all ways to create or modify instructions that the computer executes. This means you should be applying your intuitions about one of these to all the others. Some concrete advice:
That's it! I hope this helps you think about your programs in a new way, and makes you ask new questions of your development process.